structbacking_dev_info{u64id;structrb_noderb_node;/* keyed by ->id */structlist_headbdi_list;unsignedlongra_pages;/* max readahead in PAGE_SIZE units */unsignedlongio_pages;/* max allowed IO size */congested_fn*congested_fn;/* Function pointer if device is md/dm */void*congested_data;/* Pointer to aux data for congested func */// 通常为 "block"
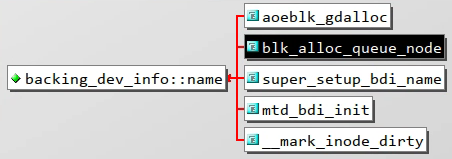
constchar*name;structkrefrefcnt;/* Reference counter for the structure */unsignedintcapabilities;/* Device capabilities */unsignedintmin_ratio;unsignedintmax_ratio,max_prop_frac;/*
* Sum of avg_write_bw of wbs with dirty inodes. > 0 if there are
* any dirty wbs, which is depended upon by bdi_has_dirty().
*/atomic_long_ttot_write_bandwidth;structbdi_writebackwb;/* the root writeback info for this bdi */structlist_headwb_list;/* list of all wbs */#ifdef CONFIG_CGROUP_WRITEBACK
structradix_tree_rootcgwb_tree;/* radix tree of active cgroup wbs */structrb_rootcgwb_congested_tree;/* their congested states */structmutexcgwb_release_mutex;/* protect shutdown of wb structs */structrw_semaphorewb_switch_rwsem;/* no cgwb switch while syncing */#else
structbdi_writeback_congested*wb_congested;#endif
wait_queue_head_twb_waitq;// bdi_class 设备
structdevice*dev;// 主设备号:次设备号
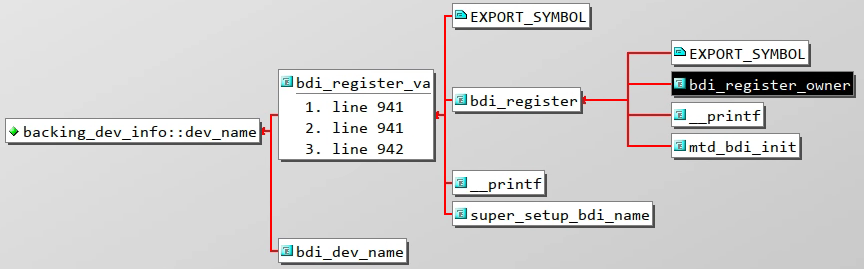
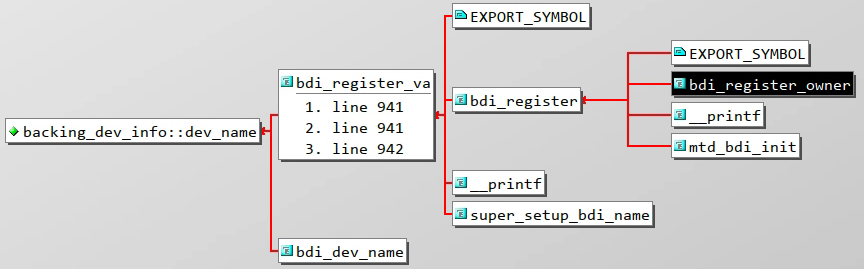
chardev_name[64];// 实际的底层设备
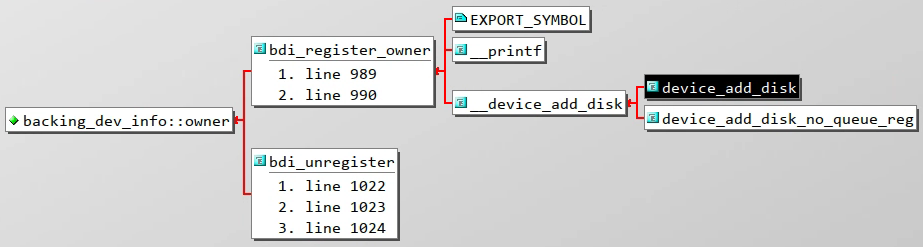
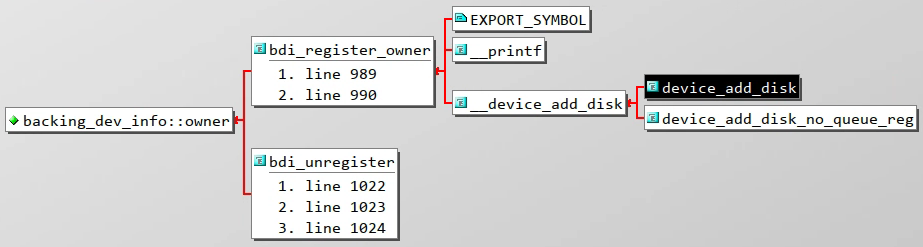
structdevice*owner;structtimer_listlaptop_mode_wb_timer;#ifdef CONFIG_DEBUG_FS
structdentry*debug_dir;#endif
};
/*
* Each wb (bdi_writeback) can perform writeback operations, is measured
* and throttled, independently. Without cgroup writeback, each bdi
* (bdi_writeback) is served by its embedded bdi->wb.
*
* On the default hierarchy, blkcg implicitly enables memcg. This allows
* using memcg's page ownership for attributing writeback IOs, and every
* memcg - blkcg combination can be served by its own wb by assigning a
* dedicated wb to each memcg, which enables isolation across different
* cgroups and propagation of IO back pressure down from the IO layer upto
* the tasks which are generating the dirty pages to be written back.
*
* A cgroup wb is indexed on its bdi by the ID of the associated memcg,
* refcounted with the number of inodes attached to it, and pins the memcg
* and the corresponding blkcg. As the corresponding blkcg for a memcg may
* change as blkcg is disabled and enabled higher up in the hierarchy, a wb
* is tested for blkcg after lookup and removed from index on mismatch so
* that a new wb for the combination can be created.
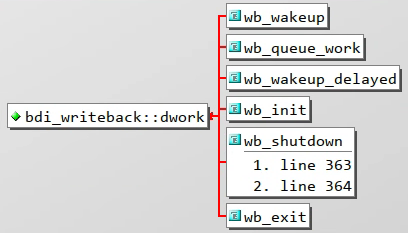
*/structbdi_writeback{structbacking_dev_info*bdi;/* our parent bdi */unsignedlongstate;/* Always use atomic bitops on this */unsignedlonglast_old_flush;/* last old data flush */structlist_headb_dirty;/* dirty inodes */structlist_headb_io;/* parked for writeback */structlist_headb_more_io;/* parked for more writeback */structlist_headb_dirty_time;/* time stamps are dirty */spinlock_tlist_lock;/* protects the b_* lists */structpercpu_counterstat[NR_WB_STAT_ITEMS];structbdi_writeback_congested*congested;unsignedlongbw_time_stamp;/* last time write bw is updated */unsignedlongdirtied_stamp;unsignedlongwritten_stamp;/* pages written at bw_time_stamp */unsignedlongwrite_bandwidth;/* the estimated write bandwidth */unsignedlongavg_write_bandwidth;/* further smoothed write bw, > 0 *//*
* The base dirty throttle rate, re-calculated on every 200ms.
* All the bdi tasks' dirty rate will be curbed under it.
* @dirty_ratelimit tracks the estimated @balanced_dirty_ratelimit
* in small steps and is much more smooth/stable than the latter.
*/unsignedlongdirty_ratelimit;unsignedlongbalanced_dirty_ratelimit;structfprop_local_percpucompletions;intdirty_exceeded;enumwb_reasonstart_all_reason;spinlock_twork_lock;/* protects work_list & dwork scheduling */structlist_headwork_list;structdelayed_workdwork;/* work item used for writeback */unsignedlongdirty_sleep;/* last wait */structlist_headbdi_node;/* anchored at bdi->wb_list */#ifdef CONFIG_CGROUP_WRITEBACK
structpercpu_refrefcnt;/* used only for !root wb's */structfprop_local_percpumemcg_completions;structcgroup_subsys_state*memcg_css;/* the associated memcg */structcgroup_subsys_state*blkcg_css;/* and blkcg */structlist_headmemcg_node;/* anchored at memcg->cgwb_list */structlist_headblkcg_node;/* anchored at blkcg->cgwb_list */union{structwork_structrelease_work;structrcu_headrcu;};#endif
};
/*
* A control structure which tells the writeback code what to do. These are
* always on the stack, and hence need no locking. They are always initialised
* in a manner such that unspecified fields are set to zero.
*/structwriteback_control{longnr_to_write;/* Write this many pages, and decrement
this for each page written */longpages_skipped;/* Pages which were not written *//*
* For a_ops->writepages(): if start or end are non-zero then this is
* a hint that the filesystem need only write out the pages inside that
* byterange. The byte at `end' is included in the writeout request.
*/loff_trange_start;loff_trange_end;enumwriteback_sync_modessync_mode;unsignedfor_kupdate:1;/* A kupdate writeback */unsignedfor_background:1;/* A background writeback */unsignedtagged_writepages:1;/* tag-and-write to avoid livelock */unsignedfor_reclaim:1;/* Invoked from the page allocator */unsignedrange_cyclic:1;/* range_start is cyclic */unsignedfor_sync:1;/* sync(2) WB_SYNC_ALL writeback *//*
* When writeback IOs are bounced through async layers, only the
* initial synchronous phase should be accounted towards inode
* cgroup ownership arbitration to avoid confusion. Later stages
* can set the following flag to disable the accounting.
*/unsignedno_cgroup_owner:1;unsignedpunt_to_cgroup:1;/* cgrp punting, see __REQ_CGROUP_PUNT */#ifdef CONFIG_CGROUP_WRITEBACK
structbdi_writeback*wb;/* wb this writeback is issued under */structinode*inode;/* inode being written out *//* foreign inode detection, see wbc_detach_inode() */intwb_id;/* current wb id */intwb_lcand_id;/* last foreign candidate wb id */intwb_tcand_id;/* this foreign candidate wb id */size_twb_bytes;/* bytes written by current wb */size_twb_lcand_bytes;/* bytes written by last candidate */size_twb_tcand_bytes;/* bytes written by this candidate */#endif
};
// mm/backing-dev.c
/*
* This function is used when the first inode for this wb is marked dirty. It
* wakes-up the corresponding bdi thread which should then take care of the
* periodic background write-out of dirty inodes. Since the write-out would
* starts only 'dirty_writeback_interval' centisecs from now anyway, we just
* set up a timer which wakes the bdi thread up later.
*
* Note, we wouldn't bother setting up the timer, but this function is on the
* fast-path (used by '__mark_inode_dirty()'), so we save few context switches
* by delaying the wake-up.
*
* We have to be careful not to postpone flush work if it is scheduled for
* earlier. Thus we use queue_delayed_work().
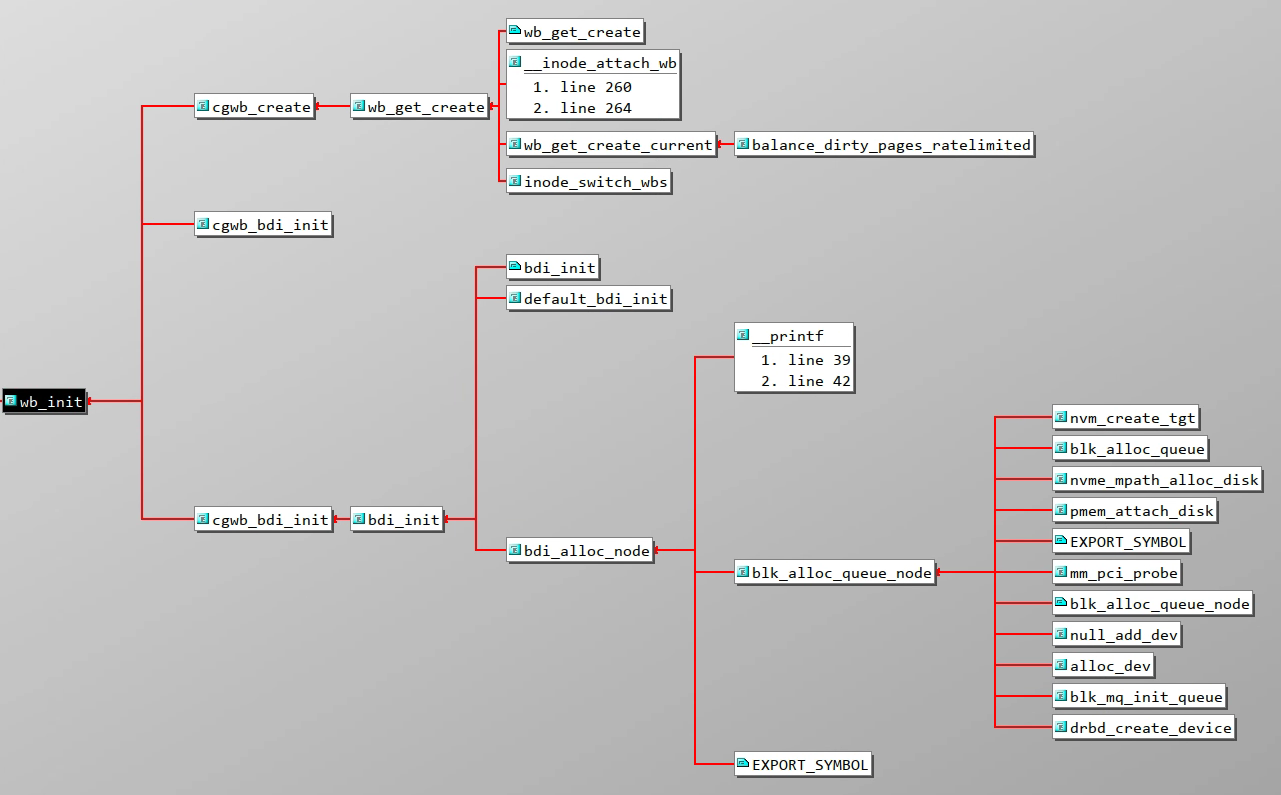
*/voidwb_wakeup_delayed(structbdi_writeback*wb){unsignedlongtimeout;timeout=msecs_to_jiffies(dirty_writeback_interval*10);spin_lock_bh(&wb->work_lock);if(test_bit(WB_registered,&wb->state))queue_delayed_work(bdi_wq,&wb->dwork,timeout);spin_unlock_bh(&wb->work_lock);}
/**
* write_cache_pages - walk the list of dirty pages of the given address space and write all of them.
* @mapping: address space structure to write
* @wbc: subtract the number of written pages from *@wbc->nr_to_write
* @writepage: function called for each page
* @data: data passed to writepage function
*
* If a page is already under I/O, write_cache_pages() skips it, even
* if it's dirty. This is desirable behaviour for memory-cleaning writeback,
* but it is INCORRECT for data-integrity system calls such as fsync(). fsync()
* and msync() need to guarantee that all the data which was dirty at the time
* the call was made get new I/O started against them. If wbc->sync_mode is
* WB_SYNC_ALL then we were called for data integrity and we must wait for
* existing IO to complete.
*
* To avoid livelocks (when other process dirties new pages), we first tag
* pages which should be written back with TOWRITE tag and only then start
* writing them. For data-integrity sync we have to be careful so that we do
* not miss some pages (e.g., because some other process has cleared TOWRITE
* tag we set). The rule we follow is that TOWRITE tag can be cleared only
* by the process clearing the DIRTY tag (and submitting the page for IO).
*
* To avoid deadlocks between range_cyclic writeback and callers that hold
* pages in PageWriteback to aggregate IO until write_cache_pages() returns,
* we do not loop back to the start of the file. Doing so causes a page
* lock/page writeback access order inversion - we should only ever lock
* multiple pages in ascending page->index order, and looping back to the start
* of the file violates that rule and causes deadlocks.
*
* Return: %0 on success, negative error code otherwise
*/intwrite_cache_pages(structaddress_space*mapping,structwriteback_control*wbc,writepage_twritepage,void*data){intret=0;intdone=0;interror;structpagevecpvec;intnr_pages;pgoff_tuninitialized_var(writeback_index);pgoff_tindex;pgoff_tend;/* Inclusive */pgoff_tdone_index;intrange_whole=0;xa_mark_ttag;pagevec_init(&pvec);if(wbc->range_cyclic){writeback_index=mapping->writeback_index;/* prev offset */index=writeback_index;end=-1;}else{index=wbc->range_start>>PAGE_SHIFT;end=wbc->range_end>>PAGE_SHIFT;if(wbc->range_start==0&&wbc->range_end==LLONG_MAX)range_whole=1;}if(wbc->sync_mode==WB_SYNC_ALL||wbc->tagged_writepages)tag=PAGECACHE_TAG_TOWRITE;elsetag=PAGECACHE_TAG_DIRTY;if(wbc->sync_mode==WB_SYNC_ALL||wbc->tagged_writepages)tag_pages_for_writeback(mapping,index,end);done_index=index;while(!done&&(index<=end)){inti;nr_pages=pagevec_lookup_range_tag(&pvec,mapping,&index,end,tag);if(nr_pages==0)break;for(i=0;i<nr_pages;i++){structpage*page=pvec.pages[i];done_index=page->index;lock_page(page);/*
* Page truncated or invalidated. We can freely skip it
* then, even for data integrity operations: the page
* has disappeared concurrently, so there could be no
* real expectation of this data interity operation
* even if there is now a new, dirty page at the same
* pagecache address.
*/if(unlikely(page->mapping!=mapping)){continue_unlock:unlock_page(page);continue;}if(!PageDirty(page)){/* someone wrote it for us */gotocontinue_unlock;}if(PageWriteback(page)){if(wbc->sync_mode!=WB_SYNC_NONE)wait_on_page_writeback(page);elsegotocontinue_unlock;}BUG_ON(PageWriteback(page));if(!clear_page_dirty_for_io(page))gotocontinue_unlock;trace_wbc_writepage(wbc,inode_to_bdi(mapping->host));error=(*writepage)(page,wbc,data);if(unlikely(error)){/*
* Handle errors according to the type of
* writeback. There's no need to continue for
* background writeback. Just push done_index
* past this page so media errors won't choke
* writeout for the entire file. For integrity
* writeback, we must process the entire dirty
* set regardless of errors because the fs may
* still have state to clear for each page. In
* that case we continue processing and return
* the first error.
*/if(error==AOP_WRITEPAGE_ACTIVATE){unlock_page(page);error=0;}elseif(wbc->sync_mode!=WB_SYNC_ALL){ret=error;done_index=page->index+1;done=1;break;}if(!ret)ret=error;}/*
* We stop writing back only if we are not doing
* integrity sync. In case of integrity sync we have to
* keep going until we have written all the pages
* we tagged for writeback prior to entering this loop.
*/if(--wbc->nr_to_write<=0&&wbc->sync_mode==WB_SYNC_NONE){done=1;break;}}pagevec_release(&pvec);cond_resched();}/*
* If we hit the last page and there is more work to be done: wrap
* back the index back to the start of the file for the next
* time we are called.
*/if(wbc->range_cyclic&&!done)done_index=0;if(wbc->range_cyclic||(range_whole&&wbc->nr_to_write>0))mapping->writeback_index=done_index;returnret;}EXPORT_SYMBOL(write_cache_pages);
staticlongwriteback_chunk_size(structbdi_writeback*wb,structwb_writeback_work*work){longpages;/*
* WB_SYNC_ALL mode does livelock avoidance by syncing dirty
* inodes/pages in one big loop. Setting wbc.nr_to_write=LONG_MAX
* here avoids calling into writeback_inodes_wb() more than once.
*
* The intended call sequence for WB_SYNC_ALL writeback is:
*
* wb_writeback()
* writeback_sb_inodes() <== called only once
* write_cache_pages() <== called once for each inode
* (quickly) tag currently dirty pages
* (maybe slowly) sync all tagged pages
*/if(work->sync_mode==WB_SYNC_ALL||work->tagged_writepages)pages=LONG_MAX;else{pages=min(wb->avg_write_bandwidth/2,global_wb_domain.dirty_limit/DIRTY_SCOPE);pages=min(pages,work->nr_pages);pages=round_down(pages+MIN_WRITEBACK_PAGES,MIN_WRITEBACK_PAGES);}returnpages;}
[PATCH] writeback: fix range handling
When a writeback_control's `start' and `end' fields are used to
indicate a one-byte-range starting at file offset zero, the required
values of .start=0,.end=0 mean that the ->writepages() implementation
has no way of telling that it is being asked to perform a range
request. Because we're currently overloading (start == 0 && end == 0)
to mean "this is not a write-a-range request".
To make all this sane, the patch changes range of writeback_control.
So caller does: If it is calling ->writepages() to write pages, it
sets range (range_start/end or range_cyclic) always.
And if range_cyclic is true, ->writepages() thinks the range is
cyclic, otherwise it just uses range_start and range_end.
This patch does,
- Add LLONG_MAX, LLONG_MIN, ULLONG_MAX to include/linux/kernel.h
-1 is usually ok for range_end (type is long long). But, if someone did,
range_end += val; range_end is "val - 1"
u64val = range_end >> bits; u64val is "~(0ULL)"
or something, they are wrong. So, this adds LLONG_MAX to avoid nasty
things, and uses LLONG_MAX for range_end.
- All callers of ->writepages() sets range_start/end or range_cyclic.
- Fix updates of ->writeback_index. It seems already bit strange.
If it starts at 0 and ended by check of nr_to_write, this last
index may reduce chance to scan end of file. So, this updates
->writeback_index only if range_cyclic is true or whole-file is
scanned.
Signed-off-by: OGAWA Hirofumi <hirofumi@mail.parknet.co.jp>
Cc: Nathan Scott <nathans@sgi.com>
Cc: Anton Altaparmakov <aia21@cantab.net>
Cc: Steven French <sfrench@us.ibm.com>
Cc: "Vladimir V. Saveliev" <vs@namesys.com>
Signed-off-by: Andrew Morton <akpm@osdl.org>
Signed-off-by: Linus Torvalds <torvalds@osdl.org>
if(wbc->range_cyclic){writeback_index=mapping->writeback_index;/* prev offset */index=writeback_index;end=-1;}else{index=wbc->range_start>>PAGE_SHIFT;end=wbc->range_end>>PAGE_SHIFT;if(wbc->range_start==0&&wbc->range_end==LLONG_MAX)range_whole=1;}// 此处省略部分代码
/*
* If we hit the last page and there is more work to be done: wrap
* back the index back to the start of the file for the next
* time we are called.
*/if(wbc->range_cyclic&&!done)done_index=0;if(wbc->range_cyclic||(range_whole&&wbc->nr_to_write>0))mapping->writeback_index=done_index;
staticlongwb_check_old_data_flush(structbdi_writeback*wb){unsignedlongexpired;longnr_pages;/*
* When set to zero, disable periodic writeback
*/if(!dirty_writeback_interval)return0;expired=wb->last_old_flush+msecs_to_jiffies(dirty_writeback_interval*10);if(time_before(jiffies,expired))return0;wb->last_old_flush=jiffies;nr_pages=get_nr_dirty_pages();if(nr_pages){// 定期回写
structwb_writeback_workwork={.nr_pages=nr_pages,.sync_mode=WB_SYNC_NONE,.for_kupdate=1,.range_cyclic=1,.reason=WB_REASON_PERIODIC,};returnwb_writeback(wb,&work);}return0;}
// mm/page-writeback.c
/*
* Start background writeback (via writeback threads) at this percentage
*/intdirty_background_ratio=10;/*
* The generator of dirty data starts writeback at this percentage
*/intvm_dirty_ratio=20;
// fs/sync.c
/*
* Sync everything. We start by waking flusher threads so that most of
* writeback runs on all devices in parallel. Then we sync all inodes reliably
* which effectively also waits for all flusher threads to finish doing
* writeback. At this point all data is on disk so metadata should be stable
* and we tell filesystems to sync their metadata via ->sync_fs() calls.
* Finally, we writeout all block devices because some filesystems (e.g. ext2)
* just write metadata (such as inodes or bitmaps) to block device page cache
* and do not sync it on their own in ->sync_fs().
*/voidksys_sync(void){intnowait=0,wait=1;// 唤醒所有 bdi 的回写线程
wakeup_flusher_threads(WB_REASON_SYNC);// 下发所有 inode 的回写任务
iterate_supers(sync_inodes_one_sb,NULL);// 调用 sync_fs() 同步文件系统的元数据
iterate_supers(sync_fs_one_sb,&nowait);iterate_supers(sync_fs_one_sb,&wait);// 回写块设备的 page cache
iterate_bdevs(fdatawrite_one_bdev,NULL);iterate_bdevs(fdatawait_one_bdev,NULL);if(unlikely(laptop_mode))laptop_sync_completion();}SYSCALL_DEFINE0(sync){ksys_sync();return0;}
// fs/sync.c
/**
* vfs_fsync_range - helper to sync a range of data & metadata to disk
* @file: file to sync
* @start: offset in bytes of the beginning of data range to sync
* @end: offset in bytes of the end of data range (inclusive)
* @datasync: perform only datasync
*
* Write back data in range @start..@end and metadata for @file to disk. If
* @datasync is set only metadata needed to access modified file data is
* written.
*/intvfs_fsync_range(structfile*file,loff_tstart,loff_tend,intdatasync){structinode*inode=file->f_mapping->host;if(!file->f_op->fsync)return-EINVAL;if(!datasync&&(inode->i_state&I_DIRTY_TIME))mark_inode_dirty_sync(inode);returnfile->f_op->fsync(file,start,end,datasync);}EXPORT_SYMBOL(vfs_fsync_range);/**
* vfs_fsync - perform a fsync or fdatasync on a file
* @file: file to sync
* @datasync: only perform a fdatasync operation
*
* Write back data and metadata for @file to disk. If @datasync is
* set only metadata needed to access modified file data is written.
*/intvfs_fsync(structfile*file,intdatasync){returnvfs_fsync_range(file,0,LLONG_MAX,datasync);}EXPORT_SYMBOL(vfs_fsync);staticintdo_fsync(unsignedintfd,intdatasync){structfdf=fdget(fd);intret=-EBADF;if(f.file){ret=vfs_fsync(f.file,datasync);fdput(f);}returnret;}SYSCALL_DEFINE1(fsync,unsignedint,fd){returndo_fsync(fd,0);}SYSCALL_DEFINE1(fdatasync,unsignedint,fd){returndo_fsync(fd,1);}
// fs/libfs.c
/**
* __generic_file_fsync - generic fsync implementation for simple filesystems
*
* @file: file to synchronize
* @start: start offset in bytes
* @end: end offset in bytes (inclusive)
* @datasync: only synchronize essential metadata if true
*
* This is a generic implementation of the fsync method for simple
* filesystems which track all non-inode metadata in the buffers list
* hanging off the address_space structure.
*/int__generic_file_fsync(structfile*file,loff_tstart,loff_tend,intdatasync){structinode*inode=file->f_mapping->host;interr;intret;err=file_write_and_wait_range(file,start,end);if(err)returnerr;inode_lock(inode);ret=sync_mapping_buffers(inode->i_mapping);if(!(inode->i_state&I_DIRTY_ALL))gotoout;if(datasync&&!(inode->i_state&I_DIRTY_DATASYNC))gotoout;err=sync_inode_metadata(inode,1);if(ret==0)ret=err;out:inode_unlock(inode);/* check and advance again to catch errors after syncing out buffers */err=file_check_and_advance_wb_err(file);if(ret==0)ret=err;returnret;}EXPORT_SYMBOL(__generic_file_fsync);/**
* generic_file_fsync - generic fsync implementation for simple filesystems
* with flush
* @file: file to synchronize
* @start: start offset in bytes
* @end: end offset in bytes (inclusive)
* @datasync: only synchronize essential metadata if true
*
*/intgeneric_file_fsync(structfile*file,loff_tstart,loff_tend,intdatasync){structinode*inode=file->f_mapping->host;interr;err=__generic_file_fsync(file,start,end,datasync);if(err)returnerr;returnblkdev_issue_flush(inode->i_sb->s_bdev,GFP_KERNEL,NULL);}EXPORT_SYMBOL(generic_file_fsync);
// mm/filemap.c
/**
* generic_file_write_iter - write data to a file
* @iocb: IO state structure
* @from: iov_iter with data to write
*
* This is a wrapper around __generic_file_write_iter() to be used by most
* filesystems. It takes care of syncing the file in case of O_SYNC file
* and acquires i_mutex as needed.
* Return:
* * negative error code if no data has been written at all of
* vfs_fsync_range() failed for a synchronous write
* * number of bytes written, even for truncated writes
*/ssize_tgeneric_file_write_iter(structkiocb*iocb,structiov_iter*from){structfile*file=iocb->ki_filp;structinode*inode=file->f_mapping->host;ssize_tret;inode_lock(inode);ret=generic_write_checks(iocb,from);if(ret>0)ret=__generic_file_write_iter(iocb,from);inode_unlock(inode);if(ret>0)ret=generic_write_sync(iocb,ret);returnret;}EXPORT_SYMBOL(generic_file_write_iter);
// include/linux/fs.h
/*
* Sync the bytes written if this was a synchronous write. Expect ki_pos
* to already be updated for the write, and will return either the amount
* of bytes passed in, or an error if syncing the file failed.
*/staticinlinessize_tgeneric_write_sync(structkiocb*iocb,ssize_tcount){if(iocb->ki_flags&IOCB_DSYNC){intret=vfs_fsync_range(iocb->ki_filp,iocb->ki_pos-count,iocb->ki_pos-1,(iocb->ki_flags&IOCB_SYNC)?0:1);if(ret)returnret;}returncount;}
 Zeus
Zeus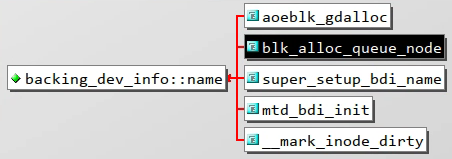
 支付宝
支付宝
 微信
微信